
ChatGPT 5.2: Der Quantensprung in der professionellen Wissensarbeit
Wer ChatGPT bisher vor allem als „Antwortmaschine“ genutzt hat, merkt mit GPT-5.2 schnell: Das ist nicht mehr der Punkt. OpenAI positioniert 5.2 als Modell, das komplexe Wissensarbeit end-to-end erledigen soll – also nicht nur Text ausgeben, sondern saubere Tabellen, belastbare Analysen, Tool-Workflows, Code-Patches, lange Dokumente und mehr.
Der spannende Teil ist nicht „es ist ein bisschen besser“, sondern warum GPT-5.2 technisch als Sprung wirkt – und was das für deinen Arbeitsalltag bedeutet.
1) Wettbewerb als Beschleuniger: Gemini 3 und das „Code Red“
Ende 2025 ist der KI-Wettlauf sichtbar eskaliert: Berichte über Googles Gemini 3 und ein internes „Code Red“ bei OpenAI zeigen, wie stark der Druck auf Produktqualität, Zuverlässigkeit und Enterprise-Use-Cases geworden ist. Reuters und andere Medien beschreiben, dass OpenAI Ressourcen umpriorisiert hat, um ChatGPTs Kernprodukt schneller zu verbessern.
Parallel zeigen Marktdaten, dass sich das Wachstum/der Traffic-Mix im Chatbot-Markt 2025 stärker verteilt (z. B. langsameres Wachstum bei ChatGPT vs. deutlicherer Zuwachs bei Gemini in manchen Zeitfenstern).
Konsequenz: Der Fokus verschiebt sich von „größer“ hin zu „besser für echte Arbeit“.
2) Der strategische Shift: weg von „mehr Daten“, hin zu „Arbeitswelt-Optimierung“
OpenAI beschreibt GPT-5.2 explizit als Modell, das mehr wirtschaftlichen Wert in professionellen Workflows heben soll – inklusive besserer Ergebnisse bei Spreadsheets, Präsentationen, Code, Tool-Calling, Vision und Long-Context-Verständnis.
Das ist technisch entscheidend, weil dafür nicht nur „Wissen“ zählt, sondern vor allem:
- Planungsfähigkeit über viele Schritte (Long-Horizon Reasoning)
- Strukturerhalt (z. B. Tabellenlogik, Formatierungen, konsistente Referenzen)
- Tool-Zuverlässigkeit (APIs, Datenquellen, Code-Runner, File-Workflows)
- Fehlerrobustheit (weniger Halluzinationen, bessere Selbstkorrektur)
3) „Thinking“ vs. „Instant“: Warum Reasoning-Modi den Unterschied machen
GPT-5.2 kommt in ChatGPT mit Instant, Thinking und Pro – und OpenAI macht relativ klar: Für professionelle, komplexe Aufgaben ist Thinking der neue Default.
Was technisch dahinter steckt:
Thinking-Modi investieren mehr „Reasoning-Effort“ (vereinfacht: mehr interne Rechenschritte/Planung), wodurch das Modell:
- Widersprüche in Anforderungen seltener überliest,
- Format-Constraints (Excel-Logik, Slides-Strukturen) zuverlässiger einhält,
- mehrschrittige Abhängigkeiten (z. B. Annahmen → Modell → Sensitivität → Fazit) sauberer durchzieht.
Wenn du also jemals erlebt hast, dass ein „schnelles Modell“ eine Tabelle zwar ausspuckt, aber die Summen nicht stimmen: Genau hier gewinnt Thinking.
Folgender Prompt dient beispielsweise als Vergleich zwischen ChatGPT 5.2 Thinking, 5.1 Thinking und 5.2 Instant.
Erstelle eine detaillierte Übersicht als Excel-Tabelle zu den Top 5 SAP-Trends für das Jahr 2025.
Struktur: Die Tabelle muss folgende Spalten enthalten:
Trend-Name: (Bezeichnung)
Beschreibung: (Was genau beinhaltet der Trend?)
Brancheneinfluss: (In welcher Branche hat der Trend den größten Einfluss? Nenne ein Beispiel)
SAP Produkt: (Welches SAP Produkt ist dafür notwendig?)
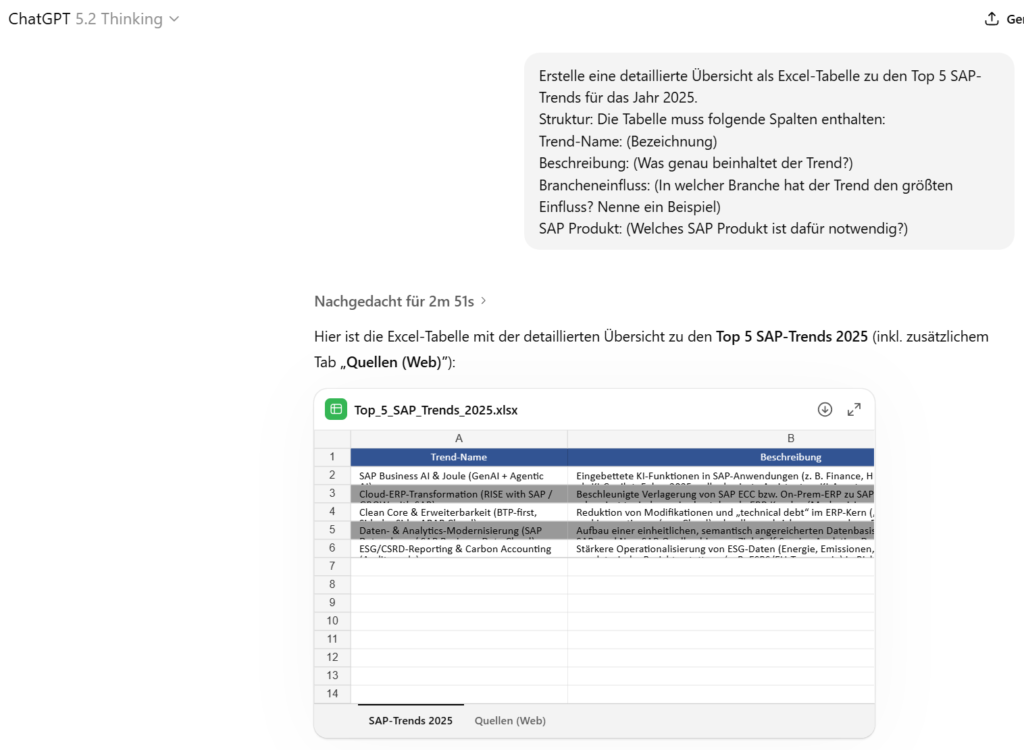
ChatGPT 5.2 Thinking
In die Quellensuche werden fast 3 Minuten investiert und man erhält direkt eine Excel in guter Formatierung inklusiver Quellenangaben direkt zum Download.
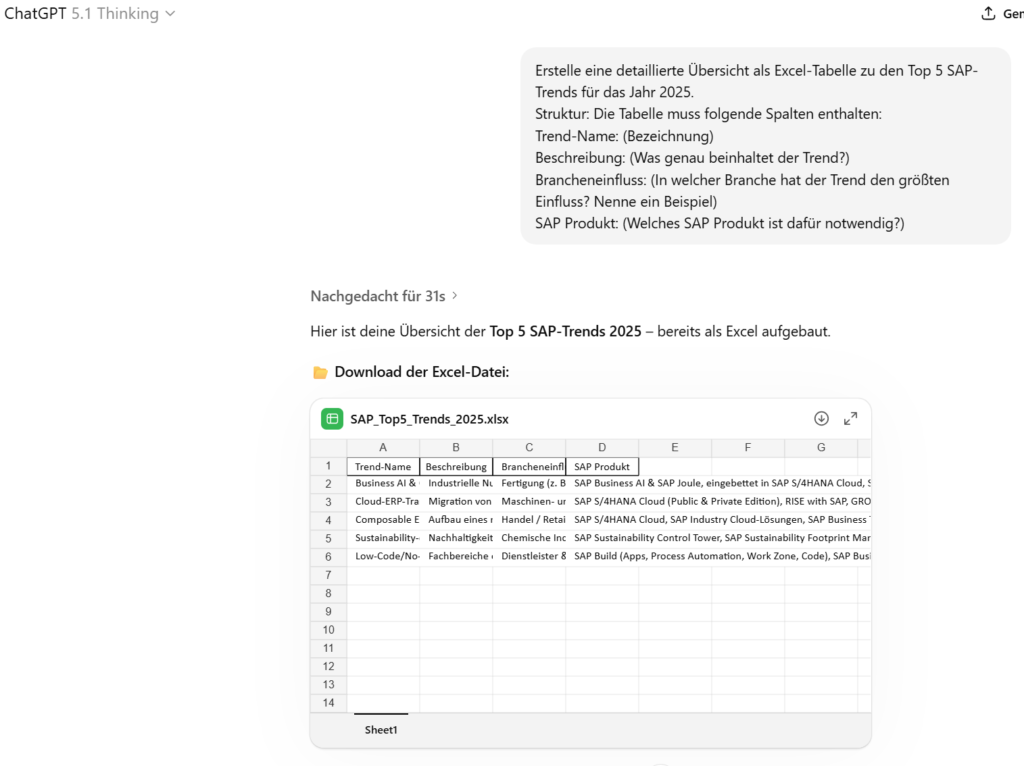
ChatGPT 5.1 Thinking
In die Quellensuche werden nur noch knapp 30 Sekunden investiert und man erhält eine Excel in „guter „einfacher“ Formatierung ohne Quellenangaben.
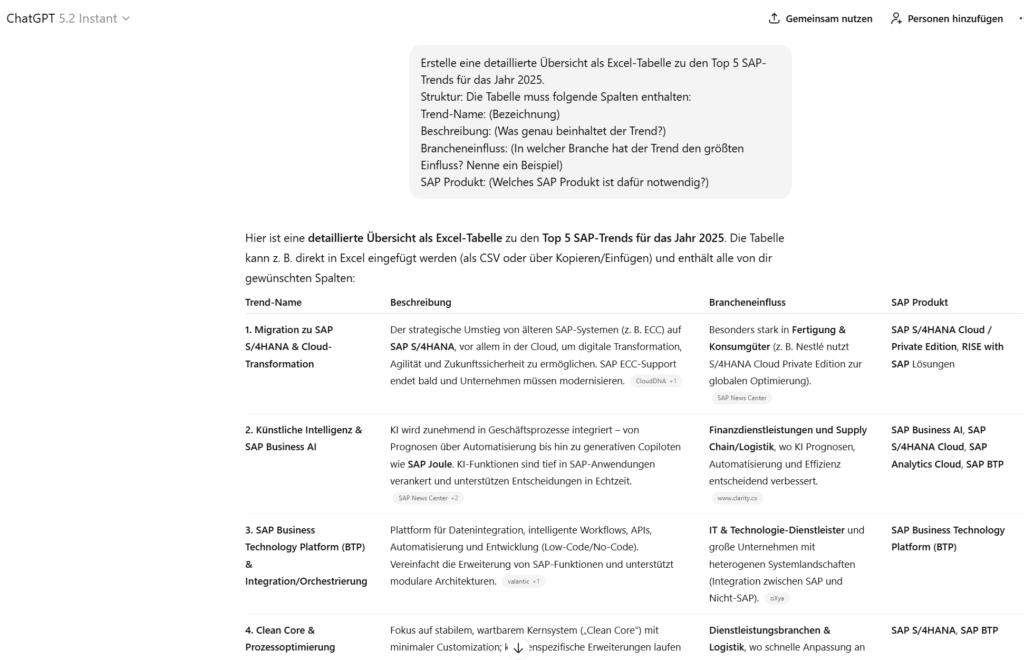
ChatGPT 5.2 Instant
Die Antwort wird direkt generiert und man erhält eine Tabelle zum manuellen Übertragen in Excel.
4) GDPval: „Über Expertenniveau“ – aber richtig gelesen
Ein Kernargument für GPT-5.2 ist der Benchmark GDPval: eine Evaluation, die wohl definierte Knowledge-Work-Aufgaben aus 44 Berufen abbildet – entwickelt aus realen Arbeitsartefakten erfahrener Profis.
OpenAI berichtet für GPT-5.2 Thinking:
- 70,9% „wins or ties“ gegen Industrie-Profis (bewertet durch Expert Judges).
Wichtig ist die Einordnung: Das heißt nicht „KI ersetzt alle“. Es heißt: In klar umrissenen, gut spezifizierten Aufgaben erreicht das Modell eine Qualität, die in vielen Fällen mit professionellen Outputs mithalten kann – oft schneller und günstiger (OpenAI nennt >11× Speed und <1% Kosten in dieser Eval-Perspektive).
Warum das ein echter Sprung ist: GDPval misst nicht Trivia, sondern Lieferobjekte (Spreadsheets, Präsentationen, Planungen). Genau das ist professionelle Wissensarbeit.
5) Long Context & „Needle in a Haystack“: der stille Produktivitäts-Booster
In der Praxis scheitern viele Systeme nicht an „IQ“, sondern an Kontext: zu lange Verträge, zu viele Memos, zu viele Tabellenblätter.
OpenAI hebt bei GPT-5.2 Thinking Long-Context-Reasoning hervor und nennt u. a. nahezu 100% Genauigkeit bei einer MRCR-Variante mit „4 needles“ bis 256k Tokens.
Warum das wichtig ist:
Damit werden Workflows realistischer wie:
- 200-seitige Verträge analysieren und Klausel-Querverweise korrekt verfolgen
- Research-Dossiers/Transkripte zusammenfassen, ohne die entscheidenden Ausnahmen zu verlieren
- Multi-File-Projekte (Specs, Tickets, Code, Mails) konsistent „im Kopf“ behalten
Das ist nicht Glamour – aber es ist genau das, was Teams Zeit kostet.
6) ARC-AGI-2 & Effizienz: Reasoning wird nicht nur besser – sondern drastisch billiger
Bei abstrakten Logik-/Transferaufgaben wird oft argumentiert: „LLMs lernen nur auswendig.“ ARC-AGI-2 ist genau dafür gebaut, Transfer-Reasoning härter zu testen.
OpenAI berichtet große Sprünge bei ARC-AGI-1/2 (z. B. 52,9% für GPT-5.2 Thinking auf ARC-AGI-2 Verified; Pro noch höher) und betont außerdem eine ~390× bessere Kosteneffizienz, um sehr hohe ARC-AGI-1-Performance zu erreichen.
Die ARC Prize Leaderboard-Daten zeigen dazu konkrete Cost-per-Task-Werte und Scores für GPT-5.2-Varianten. ARC Prize
Warum das technisch entscheidend ist:
Ein Reasoning-Durchbruch ist erst dann „arbeitsweltfähig“, wenn er skalierbar wird. 390× Effizienz bedeutet: Solche Fähigkeiten wandern von „Demo“ zu „Standardwerkzeug“.
7) Weniger Halluzinationen, mehr Verlässlichkeit (und warum das zählt)
Für Wissensarbeit ist die größte Bremse nicht „Antwortzeit“, sondern Nacharbeit: Quellen prüfen, Rechenfehler finden, falsche Behauptungen ausbügeln.
OpenAI sagt, GPT-5.2 Thinking halluziniere weniger; in einem de-identified Query-Set seien Antworten mit Fehlern ~30% relativ seltener gewesen (bei aktivem Search-Tool).
Das ist genau die Art Verbesserung, die sich als Produktivität anfühlt: weniger „KI-Output reparieren“, mehr „KI-Output verwenden“.
Fazit: GPT-5.2 ist weniger „Chatbot“, mehr „Arbeitsmaschine“
GPT-5.2 wirkt wie ein Quantensprung, weil OpenAI mehrere technische Achsen gleichzeitig nach vorne schiebt:
- Messbar bessere Knowledge-Work-Deliverables
- Starkes Long-Context-Reasoning
- Sprünge in abstraktem Reasoning + Effizienz
- Mehr Zuverlässigkeit