
90 % weniger manuelle Arbeit – funktioniert das wirklich? Mein KI-PoC für Immobiliendokumente
Was wäre, wenn eingehende Dokumente – Rechnungen, Mahnungen, Bankschreiben – vollautomatisch gelesen, zugeordnet und abgelegt würden? Ich wollte wissen, ob das technisch machbar ist, und habe es ausprobiert.
Die Ausgangsfrage
Dieser Beitrag beschreibt keinen produktiven Rollout in einem echten Büro, sondern einen Proof of Concept – also einen strukturierten Machbarkeitsnachweis. Die Grundlage dafür waren Gespräche und Recherchen darüber, wie Dokumentenprozesse in der Immobilienbranche typischerweise ablaufen. Daraus habe ich ein realistisches Szenario abgeleitet und technisch durchgespielt.
Die zentrale Frage lautete: Wie lässt sich ein solcher Prozess mit heutigen KI- und Automatisierungstools möglichst einfach, sinnvoll und schnell abbilden – und wo liegen die Grenzen?
Das Problem, das der PoC adressiert
In vielen Unternehmen – besonders in der Immobilienbranche – läuft die Dokumentenverarbeitung noch erstaunlich analog ab. Ein Schreiben kommt rein, wird gelesen, eingescannt, manuell einer Liegenschaft zugeordnet und dann digital abgelegt und weitergeleitet. Pro Dokument dauert das drei bis fünf Minuten. Klingt überschaubar, bis man hochrechnet, wie viele Dokumente täglich eintreffen. Dadurch entstehen durchaus wöchentliche kumulierte Aufwände von bis zu fünf Stunden.
Das typische Bild, das mir beschrieben wurde: Täglich landen Rechnungen, Mahnungen, Bankschreiben, Versicherungsdokumente und Hausverwaltungsunterlagen auf dem Schreibtisch – und warten darauf, manuell verarbeitet zu werden. Fehler schleichen sich ein, Fristen werden knapp, und der Aufwand frisst Kapazität, die besser investiert wäre. Auf Basis dieses Szenarios habe ich meinen PoC aufgebaut.

Warum KI mehr kann als klassisches Texterkennen
Der entscheidende Gedanke hinter dem Projekt war eigentlich einfach: Klassische OCR erkennt Text – KI versteht ihn. Während ein Scanner nur Buchstaben sieht, kann ein Sprachmodell den Kontext einordnen, den Dokumenttyp bestimmen und relevante Felder wie Betrag, IBAN oder Fälligkeitsdatum gezielt herausziehen. Das eröffnet eine ganz andere Qualität der Automatisierung.
Die technische Umsetzung erfolgte mit Make.com, einem Automatisierungstool, das verschiedene Systeme miteinander verbindet – vereinfacht gesagt: Wenn X passiert, mache Y. Dazu kam ein Sprachmodell für die eigentliche Dokumentenanalyse.
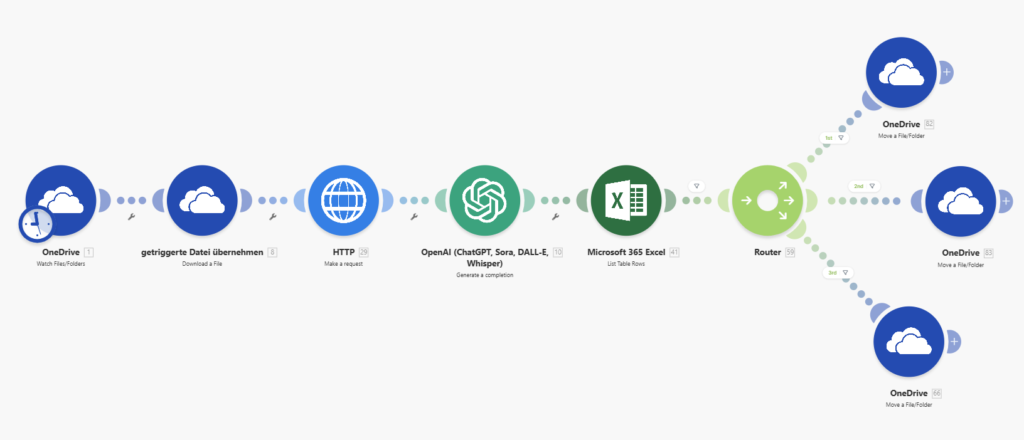
So funktioniert der Workflow
Der Ablauf beginnt, sobald ein eingescanntes Dokument in einem definierten OneDrive-Ordner landet. Make erkennt die neue Datei automatisch und übergibt sie an die KI. Die analysiert das Dokument, bestimmt seinen Typ und extrahiert alle relevanten Inhalte – zum Beispiel:
{
„typ“: „Rechnung“,
„objekt“: „Musterstraße 5“,
„betrag“: „1.245,00“,
„iban“: „DE123…“,
„faelligkeit“: „15.03.2026“
}
Aus diesem strukturierten Ergebnis leitet das System dann automatisch die nächste Aktion ab: Eine Rechnung wandert in den Zahlungsworkflow, eine Mahnung wird priorisiert und weitergeleitet, ein Bankschreiben löst eine automatische E-Mail aus, ein Versicherungsdokument landet direkt im richtigen Objektordner. Das Inventar der relevanten Immobilienobjekte ist in Excel gepflegt worüber Informationen für die weitere Verarbeitung des Workflows gezogen werden.
Die Ordnerstruktur bleibt dabei immer konsistent: jedes Dokument landet genau dort, wo es hingehört, ohne dass jemand daran denken muss.
Was der PoC gezeigt hat
Auch wenn es sich um keinen Produktivbetrieb handelt, sind die Ergebnisse des Proof of Concept aussagekräftig:

Die Tests zeigen, dass sich 80 bis 95 Prozent der typischen Dokumententypen vollständig automatisieren ließen. Sonderfälle und unbekannte Dokumenttypen würden weiterhin manuell landen – aber als bewusste Ausnahme, nicht als Dauerzustand. Ob sich diese Werte im echten Produktivbetrieb halten, wäre der nächste Schritt – der PoC legt dafür aber eine solide Grundlage.
Meine Learnings
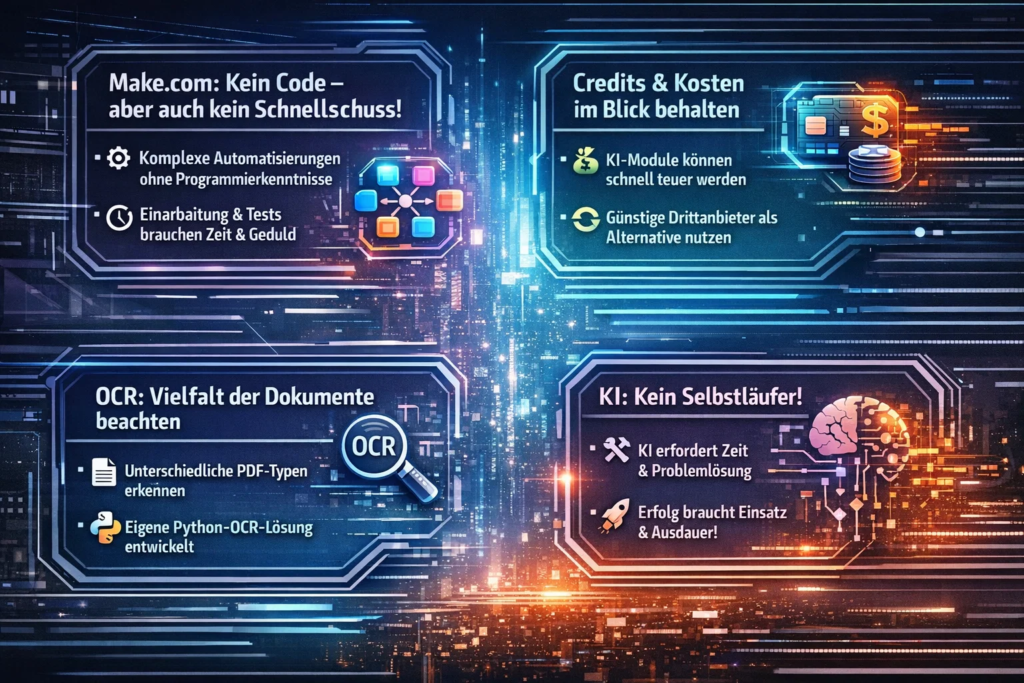
Make.com ist ein beeindruckendes Tool – und ja, es lassen sich damit komplexe Automatisierungen aufbauen, ohne eine einzige Zeile Code schreiben zu müssen. Wer aber erwartet, dass das alles in ein paar Stunden erledigt ist, wird enttäuscht. Die Einarbeitung, das Verstehen der Logik, das Testen und Debuggen: Das alles kostet Zeit. Realistische Erwartungshaltung ist hier wichtiger als Euphorie.
Credits werden schnell teuer. Make verbraucht bei jedem Durchlauf Credits – und wer die integrierten KI-Module wie den Make AI Content Extractor einsetzt, merkt schnell, dass die Kosten für einen echten Produktivbetrieb schlicht zu hoch werden. Die Lösung war, auf günstigere Drittanbieter wie PDF.co umzusteigen und diese per Schnittstelle einzubinden. Ein wichtiger Schritt, den man früh im Projekt einkalkulieren sollte.
OCR ist nicht gleich OCR. PDF-Dateien können reiner Text sein – oder gescannte Bilder. Letztere bereiten gängigen OCR-Modullösungen erhebliche Probleme: Sie erkennen schlicht nicht, was auf dem Bild steht. Nach mehreren enttäuschenden Tests habe ich eine eigene Python-OCR-Applikation auf der Google Cloud aufgesetzt und diese per HTTP-Request in den Workflow eingebunden. Das Ergebnis war die robusteste Lösung im gesamten Prozess – sie liest zuverlässig, auch bei schlechten Scans.
KI ist kein Selbstläufer. Viele Social-Media-Posts vermitteln den Eindruck, KI-Automatisierung sei schnell eingerichtet und sofort produktiv. Das halte ich für irreführend. Die Potenziale sind real und größer als je zuvor – aber sie heben sich nicht von selbst. Es braucht Arbeitszeit, Problemlösungskompetenz und die Bereitschaft, auch mal in Sackgassen zu laufen. Wer das mitbringt, kann Erstaunliches umsetzen.
Deine Meinung interessiert mich
Habt ihr ähnliche Prozesse in eurem Unternehmen? Kämpft ihr ebenfalls mit dokumentenbasierten Abläufen, die eigentlich reif für Automatisierung wären – aber irgendwie noch niemand angepackt hat? Oder habt ihr selbst schon Erfahrungen mit Make, OCR oder KI-gestützter Dokumentenverarbeitung gesammelt? Ich freue mich über jeden Kommentar, jede Frage und jeden Erfahrungsbericht – schreibt einfach unten rein, was euch bewegt.
Wer tiefer einsteigen möchte oder konkrete Fragen zu einem eigenen Projekt hat, darf mich auch gerne direkt kontaktieren: info@myaipath.de – ich antworte auf jede Nachricht persönlich.